






新烛时代6000万天使轮背后的算力底座:AI for Fusion技术栈与硬件配置全解析
时间:2026-03-22 21:23:57
来源:UltraLAB图形工作站方案网站
人气:31
作者:管理员
—— 托卡马克等离子体控制:从"几天模拟"到"毫秒响应"的算力革命
当全球AI数据中心因电力需求激增165%而面临能源危机时,一个更具野心的解决方案正在浮出水面:用AI控制可控核聚变,让人造太阳成为AI时代的终极能源底座。
新烛时代刚刚完成的6000万元天使轮融资,标志着"AI for Fusion"赛道正式进入中国硬科技投资视野。这家成立仅半年的公司,试图用人工智能解决困扰核聚变领域数十年的"控制难题"——在毫秒级时间尺度上,驯服温度高达1亿摄氏度的等离子体。
这不仅是算法的胜利,更是一场算力架构的极限挑战。
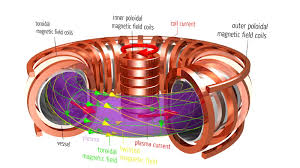
一、核心课题:托卡马克装置的三重智能闭环
新烛时代的技术路径直击托卡马克运行的三大痛点,构建观测-预测-控制的全链路智能:
1. 观测诊断(Diagnostics):从低维噪声到高维状态
-
物理现实:聚变堆内数千个传感器(磁探针、干涉仪、软X射线阵列)产生TB级多模态数据,但等离子体状态是超高维(数百万维)的连续场
-
核心难题:如何从低维、不完整、带噪声的观测中,重构等离子体电流密度分布、温度剖面、杂质浓度等高维物理量?
-
工程要求:实时性(<10ms延迟),为控制系统提供"眼睛"
2. 预测仿真(Prediction):破解"几天算几十毫秒"的困境
-
物理现实:等离子体破裂(Disruption)在毫秒内释放千兆焦耳能量,足以熔化第一壁材料
-
核心难题:传统第一性原理模拟(如GENE、GYRO回旋动理学模拟)在超级计算机上跑几天才能模拟几十毫秒物理时间,无法进行参数扫描和实时预警
-
工程要求:将计算加速1000倍,实现秒级甚至毫秒级预测
3. 实时控制(Control):毫秒级的磁场芭蕾
-
物理现实:托卡马克通过十几组磁场线圈(极向场、纵场、 shaping线圈)约束等离子体,需实时抑制锯齿振荡、边缘局域模(ELM)、电阻壁模(RWM)等不稳定性
-
核心难题:等离子体是非线性、时变、多物理场耦合的极度复杂系统,传统PID控制无法应对高维状态空间
-
工程要求:控制回路延迟<1ms,在高维动作空间(数百个控制参数)中实时优化
二、关键算法:AI与等离子体物理的深度融合
新烛时代的技术护城河在于物理信息神经网络(PINNs)与强化学习在聚变场景的深度定制:
1. 多模态数据重构算法(观测层)
-
算法架构:基于Transformer的时空序列模型 + 物理约束正则化
-
核心创新:
-
物理信息嵌入:将麦克斯韦方程组、输运方程作为软约束加入损失函数,确保重构结果满足电磁学基本定律
-
不确定性量化:贝叶斯神经网络(BNN)或集成学习,为每个重构状态提供置信区间,避免"自信的错误"
-
缺失数据插值:利用等离子体的空间相关性,通过图神经网络(GNN)处理传感器故障时的数据补全
-
2. AI代理模型(Surrogate Model,预测层)
-
算法架构:傅里叶神经算子(FNO)或深度算子网络(DeepONet)
-
核心创新:
-
算子学习:学习从初始条件到时空演化的非线性算子,实现"一次训练,任意初值快速推理"
-
多尺度融合:结合回旋动理学的微观不稳定性(离子尺度)与磁流体动力学(MHD)的宏观演化(装置尺度)
-
因果嵌入:确保代理模型满足因果律,避免传统神经网络的时间倒流悖论
-
-
加速效果:将传统CFD/动理学模拟从"几天"压缩到"秒级",加速比达10⁵~10⁶倍
3. 深度强化学习控制(控制层)
-
算法架构:Soft Actor-Critic (SAC) 或 Model Predictive Control (MPC) + 神经网络价值函数
-
核心创新:
-
安全强化学习:在探索过程中加入物理约束屏障(Control Barrier Functions),确保等离子体不会触壁(Wall Touch)
-
迁移学习:将在模拟器上训练的策略,通过Domain Randomization迁移到真实装置(Sim-to-Real)
-
多目标优化:同时优化聚变三重乘积(密度×温度×约束时间)与装置安全性
-
三、软件工具链:从第一性原理到AI部署
物理仿真与数据生成(数字孪生底座)
| 软件类别 | 推荐工具 | 用途说明 |
|---|---|---|
| 磁流体动力学(MHD) | NIMROD、JOREK、M3D-C¹ | 模拟大尺度等离子体不稳定性、破裂过程 |
| 回旋动理学 | GENE、GYRO、CGYRO | 计算离子/电子尺度微观湍流与输运系数 |
| 粒子模拟 | XGC、ORBIT | 高能粒子行为、波-粒相互作用 |
| 集成建模 | OMCore、IPS | 多代码耦合,实现从核心到边缘的全装置模拟 |
| 控制模拟 | TSC、DINA | 托卡马克控制系统设计与验证 |
AI开发与训练框架
-
深度学习框架:PyTorch(动态图更适合物理ODE/PDE嵌入)、JAX(高性能自动微分,适合PINNs)
-
科学计算库:FEniCS(有限元求解)、Dedalus(谱方法求解PDE)、DeepXDE(物理信息神经网络专用库)
-
强化学习平台:Ray RLlib(分布式训练)、Stable-Baselines3(算法原型验证)
-
实时推理优化:TensorRT(模型量化加速)、ONNX Runtime(跨平台部署)
数据管道与MLOps
-
时序数据库:InfluxDB(存储传感器高频数据)、TDengine(国产高性能时序数据库)
-
数据版本控制:DVC(管理TB级模拟数据与训练集版本)
-
实验跟踪:MLflow、Weights & Biases(记录超参数与模型性能)
四、UltraLAB核聚变AI计算硬件配置方案
核聚变AI研发呈现"两极化"算力需求:一端是需要海量并行算力的第一性原理模拟(生成训练数据),另一端是要求极低延迟的实时AI推理(控制系统)。UltraLAB提供全栈解决方案:
方案A:AI代理模型训练工作站
适用场景:训练FNO/DeepONet代理模型,处理GB-TB级模拟数据
| 组件 | 规格型号 | 技术必要性 |
|---|---|---|
| CPU | 双路 AMD EPYC 9654 (96核192线程) | 数据预处理并行加载,多Worker数据增强 |
| GPU | 2× NVIDIA RTX 4090 48GB (NVLink) 或 RTX pro 6000 96GB | 大 batch size 训练FNO(显存占用极高),多卡并行加速 |
| 内存 | 512GB DDR5-4800 ECC | 加载整个模拟数据集到内存(避免磁盘I/O瓶颈),支持内存映射 |
| 存储 |
系统:2TB NVMe 数据:16TB U.2 NVMe SSD (RAID 0) 归档:40TB NAS |
NVMe存储原始模拟数据(单案例10-100GB),快速随机读取 |
| 网络 | 双口 25GbE | 分布式训练时高速梯度同步 |
| 软件 | Ubuntu 22.04 + NVIDIA GPU Driver + CUDA 12.x + PyTorch 2.x | 完整AI开发环境,支持NVIDIA Transformer Engine |
性能指标:训练一个中等规模(1000个模拟案例)的2D托卡马克代理模型,时间从单卡的72小时缩短到4卡的18小时;支持同时加载50个案例进行在线学习(Online Learning)。
方案B:实时控制边缘计算节点
适用场景:托卡马克装置现场,毫秒级控制回路推理
| 组件 | 规格型号 | 实时性设计 |
|---|---|---|
| CPU | Intel Core i9-14900K (禁用超线程,锁定频率) 或 Xeon W-2400 | 实时Linux内核(PREEMPT_RT补丁),避免频率波动导致延迟抖动 |
| GPU | NVIDIA Jetson AGX Orin 64GB 或 RTX A4000 (单槽,75W) | 模型量化(INT8)推理,延迟<5ms;低功耗适合装置现场部署 |
| 内存 | 64GB DDR5-5600 | 足够加载控制策略网络与实时数据缓冲 |
| I/O |
NI PXIe-8840 (集成) + 光纤通道 (EtherCAT/PROFINET) |
直接连接托卡马克磁控系统,微秒级硬件触发 |
| 存储 | 1TB 工业级NVMe (带掉电保护PLP) | 实时记录控制决策日志,掉电不丢数据 |
| 系统 | Ubuntu 20.04 LTS + ROS 2 (实时中间件) | 确定性延迟保障,支持时间敏感网络(TSN) |
特色配置:
-
FPGA加速卡(可选):Xilinx Alveo U50,用于硬件级神经网络推理(延迟<1ms)
-
隔离电源:双路冗余电源,防止托卡马克脉冲功率干扰
-
抗震机箱:符合IEC 60068-2-6标准,抵御装置运行时的机械振动
方案C:高保真数字孪生服务器
适用场景:第一性原理模拟生成训练数据,验证AI模型物理一致性
| 组件 | 规格型号 | 计算特征 |
|---|---|---|
| CPU |
双路 Intel Xeon Platinum 8592+ (128核) 或 2路 AMD EPYC 9755 |
超大规模并行MHD模拟(十万级MPI进程) |
| GPU | 8× NVIDIA H100 80GB (NVLink + NVSwitch) | 原生支持FP64双精度,适合等离子体动理学PIC模拟 |
| 内存 | 2TB DDR5-4800 (16通道) | 支撑十亿网格粒子模拟的内存占用 |
| 互联 | NVIDIA Quantum-2 InfiniBand NDR (400Gb/s) | 多节点扩展,支持Exascale级聚变模拟 |
| 存储 |
并行文件系统:DDN EXAScaler 或 BeeGFS 容量:500TB+,带宽:100GB/s |
支持数千个模拟任务并发写入检查点 |
软件栈:
-
编译器:Intel oneAPI (MKL, MPI) 或 AMD ROCm
-
容器:Singularity (适合HPC环境部署GENE/XGC等代码)
-
调度:Slurm (管理千核级并行任务队列)
五、从"算法"到"装置"的工程落地建议
给核聚变AI团队的硬件实施路线图:
-
第一阶段(算法验证):使用方案A训练代理模型,利用公开托卡马克数据(如DIII-D、JET数据库)验证算法,无需接触真实装置
-
第二阶段(数字孪生):部署方案C,运行高保真模拟生成边界情况数据(如罕见的破裂模式),增强AI模型的鲁棒性
-
第三阶段(装置部署):将优化后的轻量级模型(通过知识蒸馏压缩)部署到方案B边缘节点,与托卡马克控制系统联调
关键技术提示:
-
混合精度训练:在A100/H100上使用BF16/FP16加速训练,但关键物理约束计算保持FP64,避免数值误差累积
-
模型压缩:使用知识蒸馏将大模型(教师网络)压缩为适合边缘部署的小模型(学生网络),在保持精度的同时将推理时间从10ms压缩到1ms
-
因果验证:在UltraLAB工作站上建立"反事实测试"流水线,验证AI控制器的决策是否真正基于物理因果而非数据相关性
六、总结:算力是点燃"新烛"的火柴
新烛时代的6000万融资,不仅是对"AI for Fusion"技术路线的认可,更是对工程化能力的押注。在托卡马克装置前,没有云端的唾手可得,只有本地硬实时的毫秒必争;没有捷径的近似公式,只有第一性原理的海量计算。
UltraLAB为核聚变AI提供的不仅是硬件,更是从训练到推理、从模拟到控制的完整算力生态:
-
训练端:多卡GPU并行,加速代理模型收敛,让"几天变秒级"不只是口号
-
推理端:实时边缘计算,在装置现场提供确定性延迟保障
-
模拟端:HPC级算力支撑,为AI提供高保真度的"训练教材"
当AI成为托卡马克的智慧大脑,算力就是神经系统的传导速度。在追逐人造太阳的征程上,每一毫秒的延迟,都可能让1亿度的等离子体失去控制;每一次训练的加速,都可能让清洁能源的未来提前到来。
UltraLAB图形工作站供货商:
咨询微信号:xasun001
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800

上一篇:没有了


